A blog post that uses different machine learning models to determine the smallest number of measurements necessary to determine the species of a penguin.
from LinearRegression import LinearRegressionLR = LinearRegression()LR.fit_analytic(X_train, y_train) # I used the analytical formula as my default fit methodprint(f"Training score = {LR.score(X_train, y_train).round(4)}")print(f"Validation score = {LR.score(X_val, y_val).round(4)}")print(f"The estimated weight vector is {LR.w}")
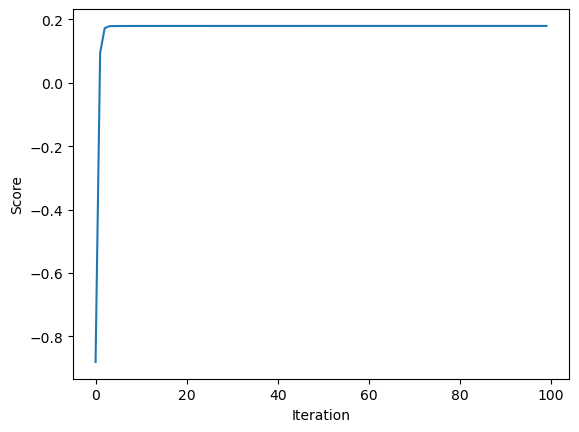
Training score = 0.1794
Validation score = 0.2142
The estimated weight vector is [0.40551937 0.79095312]
Implementing gradient descent for linear regression
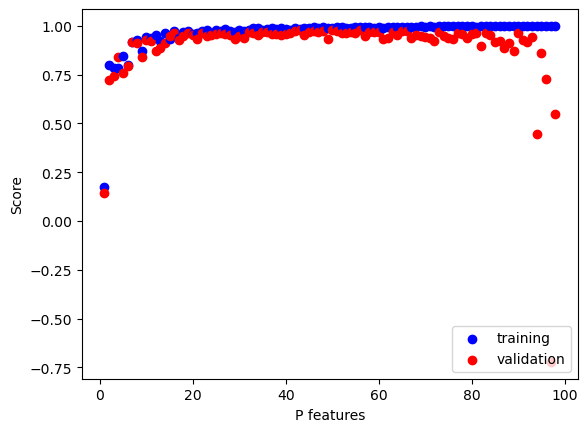
Below, we will perform an experiment in which p_features, the number of features used, will increase, while holding n_train, the number of training points, constant.
Code
#increasing p_features p_features = n_train -1for p inrange(1, p_features):#generate data X_train, y_train, X_val, y_val = LR_data(n_train, n_val, p, noise)#fit data to linear regression model LR3 = LinearRegression() LR3.fit_analytic(X_train, y_train) #score the model score_train = LR3.score(X_train, y_train) score_val = LR3.score(X_val, y_val)if p ==1: plt.scatter(p, score_train, color ="blue", label ="training") plt.scatter(p, score_val, color ="red", label ="validation") else: plt.scatter(p, score_train, color ="blue") plt.scatter(p, score_val, color ="red") #plotlabels = plt.gca().set(xlabel ="P features", ylabel ="Score")legend = plt.legend(loc='lower right')
As we can see, the training score achieves a high accuracy very quickly as we increases the number of features. However, our validation score fails to achieve a high accuracy score as we increase the number of features. This happened because our model runs into the issue of overfitting. Our model was not able to generalize well, and performed poorly when encountering new data. The model focused too closely on the noise in the training data to the extend that it negatively impacts the performance of the validation data.
LASSO Regularization
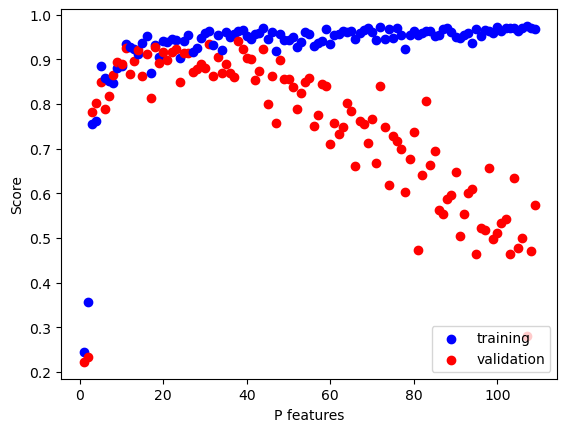
Below, we replicate the same experiment as the one above by increasing the number of features, but using LASSO instead of linear regression.
The LASSO algorithm uses a modified loss function with a regularization term:
from sklearn.linear_model import Lassop_features = n_train +10for p inrange(1, p_features):#generate data X_train, y_train, X_val, y_val = LR_data(n_train, n_val, p, noise)#fit data to LASSO L = Lasso(alpha =0.01) L.fit(X_train, y_train) #score the model score_train = L.score(X_train, y_train) score_val = L.score(X_val, y_val)if p ==1: plt.scatter(p, score_train, color ="blue", label ="training") plt.scatter(p, score_val, color ="red", label ="validation") else: plt.scatter(p, score_train, color ="blue") plt.scatter(p, score_val, color ="red") labels = plt.gca().set(xlabel ="P features", ylabel ="Score")legend = plt.legend(loc='lower right')
The LASSO algorithm performs much more poorly compared to linear regression, especially as you increase the value of the regularization strength (alpha). As we can expect, our model performs very well on the training data as the number of features used increases, but not on the validation data. The validation data experiences overfitting, just like our linear regression model, except the LASSO algorithm performs much worse on the validation data.