The algorithm updates its guesses (weights) as it runs and also keeps a record of its history of accuracy. It processes one example at a time. For a given example, it makes a prediction and checks to see if this prediction is correct. If the prediction is correct, it does nothing. Otherwise, it changes its parameters do better on this example next time around. The algorithm stops once it reaches a user-specified maximum number of steps or the accuracy is 100%.
Source Code
The algorithm has three main functions: fit(), predict(), and score().
We pass into fit() a feature matrix \(X \in R^{n \times p}\) and a target vector \(y \in R^n\). The function updates the weights and keeps track of the history of its accuracy. Its goal is to find a good \(\tilde{w}\) to separate the data points. Fit() utilizes the following function when updating its guesses:
Score() and predict() compares the target variable \(y_i\) to the predicted label \(\hat{y}_i^{(t)}\). If \(\hat{y}^{(t)}_i y_i > 0\), then we do nothing because the point is correctly classified. Otherwise, we perform the update on \(\tilde{w}\).
Code
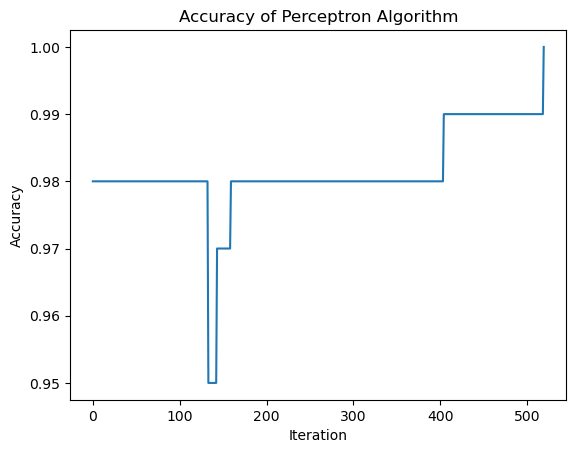
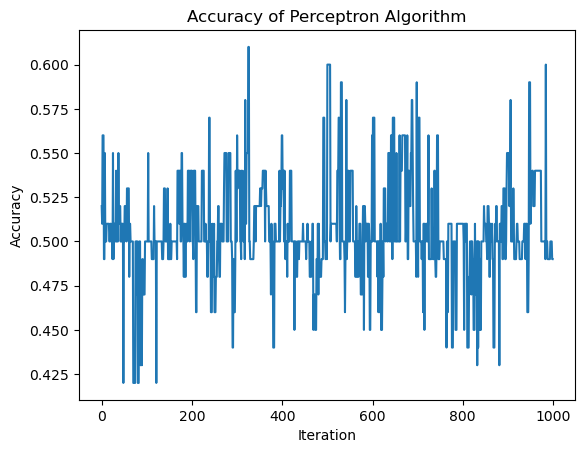
from perceptron import Perceptronp = Perceptron()p.fit(X, y, max_steps =1000)p.w print("Evolution of the score over the training period:") print(p.history[-10:]) #just the last few scoresfig = plt.plot(p.history)xlab = plt.xlabel("Iteration")ylab = plt.ylabel("Accuracy")title = plt.title("Accuracy of Perceptron Algorithm")
Evolution of the score over the training period:
[0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 1.0]
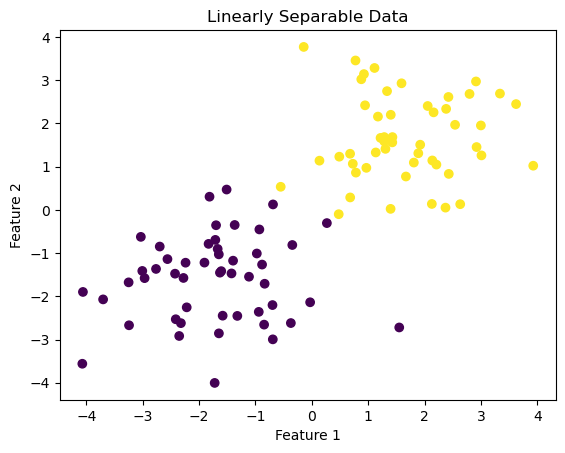
Convergence of the Perceptron Algorithm
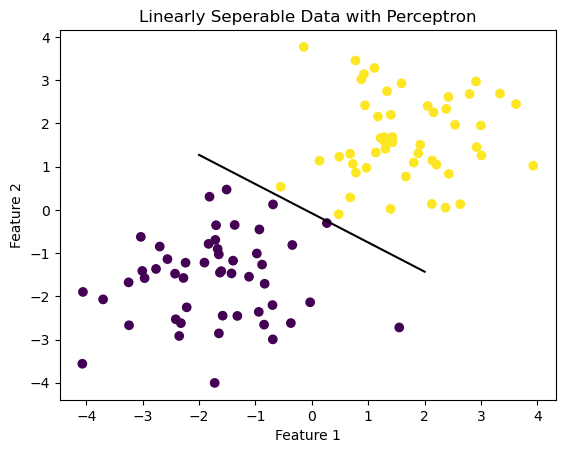
After the perceptron algorithm is run, the weight vector \(\tilde{w}\) generates a hyperplane that perfectly separates data points from both classes on either side of it.
Code
def draw_line(w, x_min, x_max): x = np.linspace(x_min, x_max, 101) y =-(w[0]*x + w[2])/w[1] plt.plot(x, y, color ="black")fig = plt.scatter(X[:,0], X[:,1], c = y)fig = draw_line(p.w, -2, 2)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")plt.title("Linearly Seperable Data with Perceptron")plt.savefig("image.jpg")
The score on this data is:
Code
p.score(X, y)
1.0
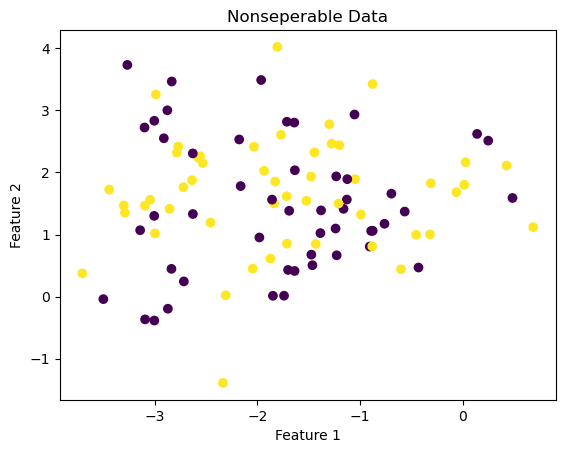
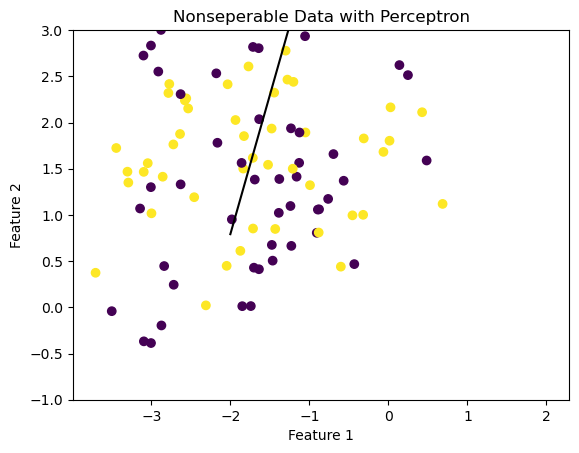
Nonseparable Data
Now suppose that \((X, y)\) is not linearly separable. In this case, the perceptron update will not converge. Below is an example of some nonseparable data with 2 features on which we will apply the perceptron on.
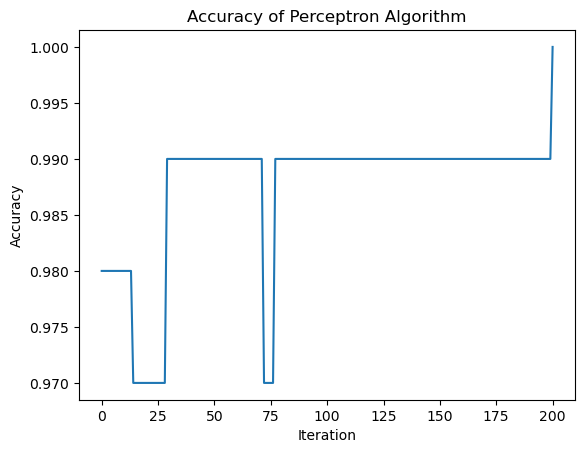
p = Perceptron()p.fit(X_n, y_n, max_steps =1000)p.wprint("Evolution of the score over the training period:") print(p.history[-10:]) #just the last few scoresfig = plt.plot(p.history)xlab = plt.xlabel("Iteration")ylab = plt.ylabel("Accuracy")title = plt.title("Accuracy of Perceptron Algorithm")
Evolution of the score over the training period:
[0.49, 0.49, 0.49, 0.49, 0.5, 0.5, 0.5, 0.5, 0.49, 0.49]
Nonconvergence of the Perceptron Algorithm
When the data is not linearly separable, the perceptron algorithm will not settle on a final value of \(\tilde{w}\) , but will instead run until the maximum number of iterations is reached, without achieving perfect accuracy.
Code
fig = plt.scatter(X_n[:,0], X_n[:,1], c = y_n)fig = draw_line(p.w, -2, 2)xlab = plt.xlabel("Feature 1")ylab = plt.ylabel("Feature 2")plt.ylim(-1,3)title = plt.title("Nonseperable Data with Perceptron")
The score on this data is:
Code
p.score(X_n, y_n)
0.5
Data with More Than 2 Features
The perceptron algorithm can also work in more than 2 dimensions. Below is an example running the algorithm on data with 5 features.
Code
p_features =6X_5, y_5 = make_blobs(n_samples =100, n_features = p_features -1, centers = [(-1.7, -1.7), (1.7, 1.7)])p = Perceptron()p.fit(X_5, y_5, max_steps =1000)p.wprint("Evolution of the score over the training period:") print(p.history[-10:]) #just the last few scoresfig = plt.plot(p.history)xlab = plt.xlabel("Iteration")ylab = plt.ylabel("Accuracy")title = plt.title("Accuracy of Perceptron Algorithm")
Evolution of the score over the training period:
[0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 0.99, 1.0]
Runtime Complexity of Perceptron
The runtime complexity does not depend on the number of data points, but it does depend on the number of features. So the runtime complexity of a single iteration of the perceptron algorithm update will depend on how many features we have. The runtime complexity is O(p).